摩尔线程国产GPU重大里程碑!千卡集群完成30亿参数大模型实训
5月27日消息,摩尔线程、无问芯穹联合宣布,双方已经正式完成MT-infini-3B 3B(30亿参数)规模大模型的实训,基于摩尔线程国产全功能GPU MTT S4000组成的千卡集群,以及无问芯穹的AIStudio PaaS平台。
本次实训充分验证了夸娥千卡智算集群在大模型训练场景下的可靠性,同时也在行业内率先开启了国产大语言模型与国产GPU千卡智算集群深度合作的新范式。
据悉,这次的MT-infini-3B模型训练总共用时13.2天,全程稳定无中断,集群训练稳定性达到100%,千卡训练和单机相比扩展效率超过90%。
目前,实训出来的MT-infini-3B性能在同规模模型中跻身前列,相比在国际主流硬件上(尤其是NVIDIA)训练而成的其他模型,在C-Eval、MMLU、CMMLU等3个测试集上均实现性能领先。
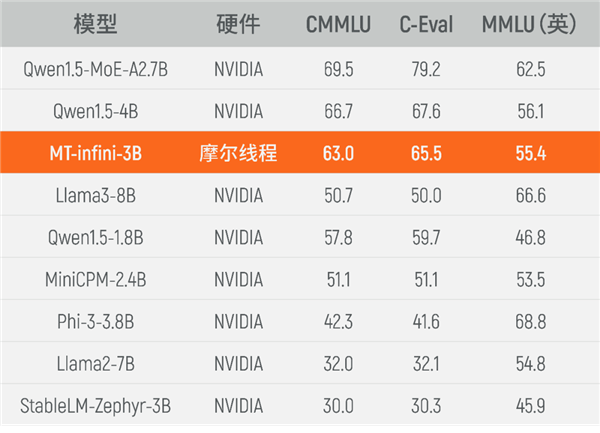
无问芯穹正在打造“M种模型”和“N种芯片”之间的“M x N”中间层产品,实现多种大模型算法在多元芯片上的高效、统一部署,已与摩尔线程达成深度战略合作。
摩尔线程是第一家接入无问芯穹并进行千卡级别大模型训练的国产GPU公司,夸娥千卡集群已与无穹Infini-AI顺利完成系统级融合适配,完成LLama2 700亿参数大模型的训练测试。
T-infini-3B的训练,则是行业内首次实现基于国产GPU芯片从0到1的端到端大模型实训案例。
就在日前,基于摩尔线程的夸娥千卡集群,憨猴集团也成功完成了7B、34B、70B不同参数量级的大模型分布式训练,双方还达成战略合作。
经双方共同严苛测试,兼容适配程度高,训练效率达到预期,精度符合要求,整个训练过程持续稳定。
抢先读
- 环球观热点:国家发改委:5月29日国内成品油价格不作调整
- 摩尔线程国产GPU重大里程碑!千卡集群完成30亿参数大模型实训
- 天津:进一步调整优化差别化住房信贷政策-环球关注
- 头条焦点:阿里影业发布2024财年业绩:强劲增长,布局未来
- 世界速看:阿里影业发布2024财年业绩:强劲增长,布局未来
- 每日信息:阿里影业发布2024财年业绩:强劲增长,布局未来
- 驻马店市驿城区人民街道建新街社区开展“六一慰问暖童心 浓浓关怀显真情”志愿服务活动
- 西平县谭店小学开展“唱红歌·迎六一”合唱比赛活动
- 每日快看:河南省农业农村厅专家验收组来西平开展省级水产良种场验收工作
- 西平县专探东沟小学举行“放飞梦想,快乐成长”庆六一文艺汇演活动 视讯
- 邓州市九龙镇卫生院:健康宣讲进校园 优化育人好环境 当前热门
- 西平县文广旅局开展《中华人民共和国民法典》宣传活动
- 西平县应急管理局机关党支部开展“争当先锋模范 助三夏生产”主题党日活动
- 西平县文广旅局深入开展文化市场安全生产摸排检查
- 淅川法院老城法庭:六一普法进校园 携手共筑童心路_世界速讯
- 环球消息!西平县嫘祖初级中学邀请县教育课程与教学发展中心检查工作
- 西平县实验小学举行“童心永向党 筑梦新时代”庆祝“六一”儿童节综合素质展演
- 驻马店开发区城市管理局:全力“护绿” 加强苗木浇水养护力度
- 当前讯息:社旗法院:晨间执行再发力 雷霆出击显威力
- 每日热闻!方城法院:锦旗表谢意 司法暖人心
- 新野法院开展第一次“豫剑执行—夏季雷霆执行月”专项执行活动 -环球关注
- 南阳市宛城区法院组织开展观看“杨根思连”先进事迹专题节目
- 驻马店市第二十五小学女子足球队荣获驻马店市第八届“市长杯”校园足球联赛季军|全球焦点
- 邓州法院:爱心敲门 情暖童心
- 当前播报:巩义市法院到新野县法院交流营商环境工作
- 西峡法院:成立山茱萸法庭 服务药材产业大发展
- 镇平县法院:诉前调解典型案例 绘就镇法新“枫”景_快播
- 西平县住建局开展房地产市场“双随机、一公开”联合检查工作
- 环球简讯:遂平县花庄镇:网格化管理为“三夏”生产护航
- 深度剖析新锐茶饮荷田水铺:听名字就有点苦的中药茶饮是好生意?
- 环球看点!港股市场正回暖 上市储备企业数量持续增加
- 【环球速看料】多家上市银行中期分红议案获股东大会通过
- 即时焦点:港股市场正回暖 上市储备企业数量持续增加
- 推动房企高质量发展 大名城稳健经营资产持续优化
- 国资委:推进国有企业整合重组、有序进退、提质增效 天天新消息
- 以便捷“收旧”推动积极“换新” 多地加快再生资源回收体系建设 全球视讯
- 国资委:推进国有企业整合重组、有序进退、提质增效 播资讯
- 清“挂案” 卸“包袱”——西平县检察监督助力企业“轻装”前行
- 爱心汇聚 热血传递——西平县焦庄乡无偿献血志愿活动火热进行|通讯
- 环球速递!西峡农商银行:“增信赋能”让乡村振兴更出彩
- 确山县城管局开展急救知识和技能培训 全球微速讯
- 驻马店经济开发区开源办事处大刘庄村党支部组织开展“学习先进楷模 争做时代先锋”主题党日活动
- 天天讯息:邓州市水务集团自来水有限公司:做好水质监测 优化健康环境
- 罗山县市场监管局莽张市场监管所扎实推进农民专业合作社、家庭农场年报工作 环球热点评
- 大自然家居集团董事长佘学彬谈德智家:不忘初心,聚焦刚需、锤炼品质
- 观速讯丨邓州市住建局:强化业务培训 优化服务环境
- 西平县人民医院:来自“娘家人”的温暖 每日动态
- 邓州市古城实验小学:庆“六一”戏曲展演 优化育人好环境|当前聚焦
- 河南国韵光照酒业集团:举办迎端午冰雕黄酒上市厂商联谊洽谈会
- 驻马店开发区城市管理局持续开展餐饮场所油烟治理和燃气安全专项检查
- 福田汽车呼吁共筑行业清朗环境 以坚守与创新引领良性发展
- 驻马店市回族小学举办“书香溢彩”读书月诵读比赛|今日要闻
- 驻马店市第二十一小学党支部开展“恪守‘六大纪律’ 筑牢思想根基”学习研讨会
- 世界速递!乘“数”而上蓄势向“新” 开辟增长新空间
- 中国人民银行190个县域派出机构挂牌
- 文旅领域设备更新实施方案出台 推动游乐设施、演艺设备等升级
- 直播大湾区丨“粤来粤美”:探寻文旅融合 赋能乡村振兴
- 海南海口:产销对接助力荔枝果农解烦忧
- 全国产粮第一大省黑龙江春耕生产已全面告捷
- 焦点消息!中国航天员“太空行走”盘点
- 迈进“服务升级元年” 欧派坚定大家居战略勇攀新峰|世界速读
- 【全球报资讯】驻马店市生态环境局西平分局开展农村环境整治成效现场检查工作
- 世界热议:逐梦红领巾 争做好队员——驻马店实验小学举行新队员入队仪式
- 新县:举行医疗卫生安全事件应急演练
- 信阳市人大常委会来息县视察调研校园安全暨“双减”工作 环球观热点
- 多部门推出政策“组合拳” 促进房地产平稳健康发展
- 花园城市建设与城市更新同频推进 焦点速读
- 智慧助老 电信相伴——中国电信爱心翼站服务在身边
- 商城县观庙镇:“一村一品”兴村富民_天天看点
- 水利部门采取多种措施应对汛情
- 售价20.08万-25.58万,沃尔沃纯电SUV EX30正式上市
- 每日消息!深化五心守护伴知音 从故宫到凡尔赛宫成都站暨神龙汽车32周年庆开启
- 环球即时看!保乐力加中国携手联合国训练研究所发起大学生预防酒驾主题科普行动
- 涨价策略显效,业绩大涨的香奈儿:继续涨价
- 西平县柏苑街道全力以赴开展抗旱抢种工作
- 邓州市水务集团自来水有限公司:守护用户安全饮水 优化居民健康环境 快看
- 平安产险2023年度企业社会责任报告:坚守金融为民初心 以高质量发展助力强国建设
- 西平县重渠贾桥小学举行新少先队员队前教育 世界关注
- 资讯:遂平县花庄镇开展移风易俗主题宣传月活动
- 中医传承——香港中医药油世家黄天赐教授揭秘止痛方
- 【环球速看料】玩转AI!西南大学人工智能学院科普课解锁“神奇的人工智能”
- 3440亿!大基金三期成立,或将发力关键设备材料零部件投资 精选
- 3440亿!大基金三期成立,或将发力关键设备材料零部件投资
- 全球今日讯!访民情 问需求 谋发展——西平县人民检察院检察长带案下乡走访调研
- 实现多个首次!中国航天员已圆满完成14次出舱活动
- 【练精兵 铸警魂】 泌阳法院司法警察大队选派5名干警参加全市法院业务骨干培训班
- 全球观热点:浉河区武胜关街道办事处筹建处开展“全市安全日”防汛应急演练
- 天天快报!在上海嘉定感受智能汽车创新“热带雨林”
- 世界要闻:驻马店市驿城区东风街道:为儿童撑起“绿色天空” 东风街道“扫黄打非”进行时
- 西平县人和乡召开第十二届人民代表大会三次会议 世界热点评
- 每日时讯!邮储银行邓州支行:进企业送惠贷 优化金融服务环境
- 驻马店市驿城区新华街道团工委举办六一“心”成长健康讲座-世界独家
- 驻马店市第二人民医院:七旬老人的两感谢信|环球实时
- 驻马店市驿城区老街街道飞龙社区:党建引领新风尚 践行分类齐参与_世界快看
- 今日快看!固始县人民医院:医者暖人心 锦旗寄真情
- 驻马店市驿城区朱古洞乡:风吹麦浪党旗红 助农惠民促振兴
- 全球即时看!固始县李店镇:科技赋能 助力乡村振兴
- 精选!潢川县卫健委组织开展全县妇幼健康重点工作督导质控
- 全球观焦点:邓州法院:商会来了“法律特派员”
- 息县组织开展5月份“全市安全日”应急演练活动-天天关注